

The conversation that keeps going nowhere
I’ve sat through dozens of sprint retrospectives where someone says, “We really need to address our technical debt”. Everyone nods solemnly. Maybe it gets added to a backlog. And then… nothing happens. Three months later, same retro, same lament.
For years, I thought this was a prioritization problem. Leadership doesn’t understand. Product keeps pushing features. The usual suspects. But after inheriting a few legacy systems and watching capable teams struggle with codebases that looked fine on the surface, I started to suspect something else was going on.
The code wasn’t the problem. The problem was that nobody could tell me why the code was the way it was.
There’s a particular moment I keep coming back to. I was three weeks into a new role, staring at a service that handled payment reconciliation. The code itself was reasonably clean. Decent test coverage. But there was this one function that did something deeply weird with timezone conversions, and when I asked about it, I got the answer that haunts every engineer who’s ever inherited a system: “I don’t know, but don’t touch it. Last person who changed that caused a production incident.”
That function wasn’t technical debt in the way we usually talk about it. It was working. It was tested. But the context for why it existed had completely evaporated, and that missing context was costing us. We couldn’t confidently modify it, couldn’t refactor around it, couldn’t even assess whether it was still necessary. We were paying interest on a loan nobody remembered taking out.
What Ward Cunningham actually meant
The term “technical debt” comes from Ward Cunningham, one of the original signatories of the Agile Manifesto. And here’s the thing: his original metaphor was way more nuanced than how most teams use the phrase today.
Cunningham wasn’t talking about sloppy code. He was describing a deliberate trade-off. You ship something that reflects your current understanding of the problem, knowing that understanding will evolve. As you learn more, there’s a gap between what the code expresses and what you now know to be true. That gap is the debt. The “interest” is the extra effort required to work around that gap until you go back and realign the code with your improved understanding.
This is a knowledge problem, not a craftsmanship problem.
Somewhere along the way, the industry flattened “technical debt” into “code we’re not proud of.” Missing tests, duplicated logic, that class someone wrote at 2 AM before a deadline. And sure, those things have costs. But they’re visible costs. You can point at them. You can measure cyclomatic complexity or test coverage or whatever metric makes your engineering manager happy.
The debt Cunningham was describing is harder to see. It’s the decision rationale that never got written down. It’s the constraint that made sense in 2019 but nobody remembers evaluating since. It’s the workaround that became permanent because the person who understood the original problem left the company.
I call this context debt, and in my experience, it’s often more expensive than the code debt we spend all our time measuring.
How decisions become folklore
Let me walk you through how this typically plays out. It’s a pattern I’ve seen repeat across every team and codebase I’ve worked with.
Stage 1: The Decision
Someone makes a reasonable choice under real constraints. Maybe you pick a particular database because of a specific performance requirement. Maybe you structure an API a certain way because of how a key customer needs to integrate. Maybe you skip building a feature the “right” way because you need to hit a launch window and you plan to revisit it.
At this moment, the context is fresh. Everyone involved understands the trade-off.
Stage 2: The Assumption
Time passes. The people who made the decision move to other projects or leave the company. New team members join. They see the code, and because there’s no record of the original reasoning, they assume the current implementation reflects best practices or immutable requirements. “This is how we do things here.”
Stage 3: The Constraint
The assumption hardens into a constraint. Now it’s not just “this is how we do things” but “this is how we must do things.” People build new features that depend on the existing structure. The cost of changing it grows. Even if someone questions it, the response is often, “We’d have to change too much.”
Stage 4: The Incident (or the Slow Bleed)
Eventually, the world changes in a way that conflicts with the original decision. A scaling requirement, a security vulnerability, a new integration need. And now you have a problem. The original trade-off no longer makes sense, but nobody knows it was a trade-off in the first place. It looks like a fundamental architectural choice. Changing it feels dangerous, and since nobody understands the original constraints, it’s hard to assess what might break.
Sometimes this surfaces as a dramatic incident. More often, it’s a slow bleed: features that take longer than they should, engineers who are afraid to touch certain areas, operational issues that keep recurring without a clear root cause.

What context debt actually looks like
If you’re wondering whether your team is carrying context debt, here are some symptoms I’ve learned to watch for.
In delivery:
- Estimates balloon for changes that “should be simple”
- Engineers spend significant time in code archaeology before making changes
- Pull request reviews focus heavily on what but rarely on why
- New team members take months to feel confident making changes independently
- Certain areas of the codebase have informal “owners” because nobody else will touch them
In operations:
- Incidents have root causes like “unexpected interaction between systems”
- Postmortems frequently mention “we didn’t know this dependency existed”
- Runbooks contain steps that nobody understands but everyone follows religiously
- Monitoring alerts that everyone acknowledges but nobody investigates because “it always does that”
In team dynamics:
- Heavy reliance on specific individuals for institutional knowledge
- “Ask Sarah, she’s been here the longest”
- Resistance to refactoring driven by fear rather than reasoned risk assessment
- New hires asking questions that nobody can answer
One of the more insidious aspects of context debt is that it often looks like other problems. Slow velocity might seem like a skills issue. Frequent incidents might seem like a quality issue. But sometimes the underlying cause is that your team is navigating a minefield of invisible constraints that nobody can see clearly because the map was never drawn.
The debt types your team is actually carrying
It helps to have language for distinguishing different kinds of debt. Here’s a simple taxonomy I’ve found useful:
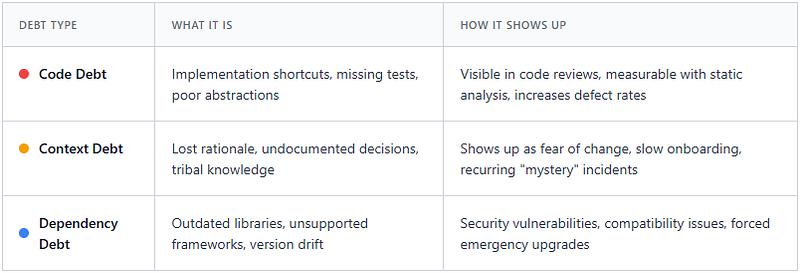
Code debt gets the most attention because it’s the most visible. Dependency debt has gotten more attention lately, especially with the supply chain security concerns that have dominated discussions through 2025 and into 2026. The recent push toward SBOMs (Software Bills of Materials) and automated dependency tracking has made this category much more tractable.
Context debt remains the hardest to measure and the easiest to ignore. Which is unfortunate, because it tends to compound the other types. Code debt is easier to pay down when you understand why the code exists. Dependency upgrades are less scary when you know what constraints drove the original version choice.
Lightweight countermeasures that actually work
Okay, so context debt is real and expensive. What do we do about it?
I want to be careful here, because the worst thing you can do is respond to a knowledge problem by creating a documentation bureaucracy. I’ve seen teams implement heavyweight processes that theoretically capture everything but practically capture nothing because engineers route around them.
The goal is to make capturing context cheap enough that it actually happens. Here are three practices that have worked for me and for teams I’ve coached.
1. Mini-ADRs (Architectural Decision Records)
Full ADRs can feel like overkill for many decisions, and when something feels like overkill, people don’t do it. A mini-ADR strips the format down to the essentials: what was decided, why, and what alternatives were considered.
Template:
# ADR: [Short descriptive title]
**Date:** YYYY-MM-DD
**Status:** Accepted | Superseded | Deprecated
**Context:** What situation or problem prompted this decision?
**Decision:** What are we doing?
**Rationale:** Why this approach over alternatives?
**Alternatives considered:** What else did we evaluate?
**Consequences:** What are the known trade-offs or future implications?Example (sanitized from a real project):
# ADR: Use polling instead of webhooks for payment status updates
**Date:** 2025-09-15
**Status:** Accepted
**Context:** We need to track payment status from our payment processor.
They offer both webhook notifications and a status polling API.
**Decision:** Use polling on a 30-second interval rather than webhooks.
**Rationale:** Our current infrastructure doesn't have a reliable way to
handle webhook delivery failures and retries. Building that properly is
estimated at 3 weeks. Polling is less efficient but works reliably with
our current setup. Payment status updates are not time-critical for our
use case (batch processing runs hourly).
**Alternatives considered:**
- Webhooks with basic retry: Rejected due to risk of missed updates
- Third-party webhook relay service: Adds external dependency, cost unclear
- Build proper webhook infrastructure: Correct long-term, but delays launch
**Consequences:** Higher API usage, slight increase in processing latency.
Should revisit when we build event infrastructure (tentatively Q2 2026).The key insight is that this took maybe ten minutes to write, and it will save hours of confusion later. When someone in 2027 asks “why are we polling instead of using webhooks?”, the answer exists.
2. Review prompts that surface “why”
Code review is a natural point to capture context, but most review processes focus on the what: Does this code work? Is it tested? Does it follow our patterns?
Adding explicit prompts for why doesn’t require changing your tools. It just requires changing your habits. I’ve had success adding a simple section to pull request templates:
## Context for future readers
- What problem does this solve?
- Why this approach?
- What would you warn a future developer about?The “what would you warn a future developer about” question is particularly useful. It surfaces the constraints and edge cases that often get lost. “This looks weird but it’s working around a bug in version X of the payment SDK” is exactly the kind of context that disappears.
Some teams have started integrating this with AI-assisted documentation, which has matured considerably over the past year. Tools that can draft contextual documentation from PR descriptions and commit histories are genuinely useful now, though they work best as a starting point that humans refine rather than a replacement for human judgment about what’s actually important.
3. Debt triage without blame
Every team I’ve seen successfully manage technical debt does some form of regular triage. But the key word is “regular.” Ad-hoc debt discussions tend to turn into complaint sessions. Scheduled triage with a clear format turns debt into something you manage rather than something that just accumulates.
A lightweight cadence that works: 30 minutes every two weeks, focused on three questions.
- What new debt did we take on? (Not to shame anyone; just to acknowledge it consciously)
- What existing debt caused friction in the last sprint? (This surfaces the debt that’s actually costing you)
- What’s one debt item we can pay down in the next sprint? (Keeps the backlog from becoming a graveyard)
The framing matters. “Debt triage” not “debt review.” Triage implies you’re making practical decisions about what to address given limited resources, not conducting a quality audit. This isn’t about whether the debt should exist; it’s about whether and when to pay it down.
The folklore detection checklist
One practical tool I’ve developed is a checklist for identifying areas where context has degraded into folklore. Folklore, in this context, means knowledge that exists only as oral tradition, unquestioned assumptions, or vague warnings.
Run through these indicators periodically, especially when onboarding new team members:
Warning signs:
- [ ] There’s code that “nobody touches” without a documented reason why
- [ ] Runbooks contain steps explained as “just do it, it works”
- [ ] Certain error messages prompt “restart and hope” as the response
- [ ] Configuration values that “must be set this way” but nobody knows why
- [ ] Features that are “temporarily disabled” and have been for over a year
- [ ] Comments in code that say “DO NOT CHANGE” without explanation
- [ ] Slack threads or old tickets are cited as the “documentation” for decisions
- [ ] Knowledge is concentrated in one or two people (“ask them, they know”)
- [ ] New engineers repeatedly ask the same questions with no written answers
- [ ] Postmortems frequently cite “unexpected behavior” in long-standing systems
If you’re checking more than three or four of these boxes, you’re probably carrying significant context debt. The checklist doesn’t tell you what to do about it, but it helps you see the problem clearly, which is the first step.
A 30-day adoption plan for normal teams
Big process changes rarely stick. Small habit changes sometimes do. Here’s a realistic plan for introducing these practices without turning it into a big initiative.
Week 1: Make debt visible
- Run the folklore detection checklist with your team
- Identify three to five areas where context has clearly degraded
- Don’t try to fix anything yet; just document what you find
Week 2: Start capturing new decisions
- Introduce the mini-ADR template
- Commit to writing one ADR per week as a team (just one, to build the habit)
- Add the “why” prompts to your PR template
Week 3: Establish the triage cadence
- Schedule your first 30-minute debt triage session
- Focus on items from your Week 1 list
- Pick one small item to address in the current sprint
Week 4: Reflect and adjust
- What worked? What felt like overhead?
- Adjust the templates based on what your team actually finds useful
- Commit to continuing the triage cadence for another month before evaluating
The goal by day 30 isn’t perfection. It’s establishing habits that compound over time. A team that writes one ADR per week for a year has 52 decisions documented. That’s a meaningful knowledge base, and it costs maybe an hour of total effort per week.
What success looks like
How do you know if this is working? I’m wary of vanity metrics here. “Number of ADRs written” doesn’t mean much if nobody reads them.
Instead, I’d watch for these signals:
Leading indicators (early signs things are improving):
- New team members ramp up faster
- Engineers spend less time in “archaeology mode” before making changes
- PR discussions include more reasoning, not just implementation feedback
- Debt triage sessions surface items proactively rather than reactively
Lagging indicators (longer-term improvements):
- Reduced time to change critical systems
- Fewer incidents attributed to “unexpected interaction”
- More confidence in refactoring (measured by actual refactoring happening)
- Knowledge silos start to dissolve
If you’re working in a metrics-driven organization, the DORA metrics (deployment frequency, lead time, change failure rate, mean time to recovery) can all be influenced by context debt. I’ve seen teams improve lead time significantly just by making it safer to change existing code through better context documentation. That said, don’t expect to draw a clean causal line from “we started writing ADRs” to “our deployment frequency went up.” These practices reduce friction and risk, which enables other improvements. The relationship is real but indirect.
The commit message upgrade
One small change that punches above its weight: improving commit messages to include rationale. This isn’t a new idea, but it’s consistently underutilized.
Before:
fix: update timezone handling in reconciliation serviceAfter:
fix: update timezone handling in reconciliation service
The previous implementation assumed all timestamps from the payment
processor were in UTC. As of their v3.2 API update (November 2025),
timestamps now include timezone info but default to the merchant's
configured timezone, not UTC.
This change explicitly converts to UTC on ingestion rather than
assuming it. The previous behavior caused reconciliation mismatches
for merchants outside UTC timezones.
See: JIRA-4521, payment processor changelog v3.2The second version takes an extra two minutes to write. But when someone runs git blame on that file in 2028, they'll understand not just what changed but why it changed and what problem it solved. That's context preserved at almost zero cost.
I’ve worked with teams that adopted a simple rule: any commit touching core business logic or working around external system behavior must include a “why” in the commit body. It felt like overhead for about two weeks, then became habit. The payoff comes months later when you’re debugging something and the commit history actually tells a story instead of just listing changes.
A note on AI-assisted documentation
I’d be remiss not to mention how the tooling landscape has shifted here. Through 2025 and into 2026, we’ve seen a real maturation in AI tools that can help with documentation and context capture. Copilot and similar tools can now generate reasonable first drafts of ADRs from PR descriptions. Some teams are experimenting with automated “context summaries” that synthesize information from commits, tickets, and discussions.
My take: these tools are genuinely useful as accelerants, not replacements. An AI can draft a decision record, but a human needs to verify that it captured the actual reasoning and not just a plausible-sounding reconstruction. The risk is that teams start treating AI-generated documentation as ground truth when it’s really just a sophisticated summary of what was written down, which may or may not reflect the real decision-making process.
Use the tools to lower the friction of documentation. But keep humans accountable for the accuracy of the “why.”
The real payoff
I want to circle back to where we started: that payment reconciliation function with the weird timezone handling that nobody could explain.
About six months after joining that team, we finally bit the bullet and investigated. It took two engineers a full week to trace the history through git logs, old Jira tickets, and Slack archives. What we found was fascinating: the weird timezone logic was a workaround for a bug in a third-party library that had been fixed three years earlier. The workaround was no longer necessary. It was just… there, being carefully preserved and worked around because nobody knew it could be removed.
We deleted about 200 lines of code that week. The tests still passed. The system still worked. We’d been maintaining and tiptoeing around code that served no purpose, purely because the context for why it existed had been lost.
That’s the tax you pay on context debt. Not just the incidents and the slow delivery, but the accumulated cruft of decisions that made sense once and now just add weight. Every “don’t touch this” that can’t be explained is potentially a constraint that no longer needs to exist.
Where to go from here
If you’ve made it this far, you’re probably already thinking about areas in your own codebase where context has gone missing. Good. That awareness is the starting point.
My challenge to you: pick one area of your system that feels scary to change, and spend an hour doing archaeology. Trace the git history. Find the original tickets or discussions if they exist. Talk to people who were there. Then write it down, even if it’s just a few paragraphs in a markdown file.
You’ll likely discover one of two things. Either the constraints are real and now you understand them, which makes the code less scary. Or the constraints are no longer valid, and you’ve just identified an opportunity to simplify.
Either way, you’ve started paying down the debt.
For teams that want to go further: try the 30-day plan. It’s low commitment and reversible. If it doesn’t work for your team, you’ve lost a few hours. If it does work, you’ve established habits that will compound for years.
And if you do try it, I’d genuinely love to hear how it goes. What worked, what didn’t, what you adapted for your context. The practices I’ve described here evolved from trial and error across multiple teams, and they’ll keep evolving as teams find better approaches.
The conversation about technical debt has been stuck for a long time. Maybe if we start talking about context instead of just code, we can finally make some progress.
Want the templates from this article in a ready-to-use format? I’ve put together a small GitHub repo with the mini-ADR template, the folklore detection checklist, and a sample debt triage agenda. Feel free to fork it and adapt it for your team.